爬虫学习路线第二站 - BeautifulSoup库的使用
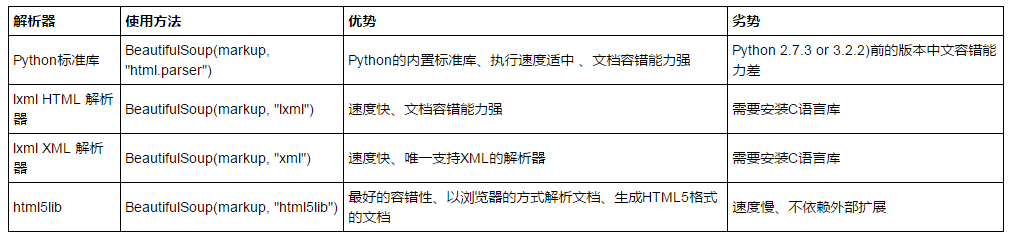
常用解析库
BeautifulSoup的基本使用
|
|
BeautifulSoup标签选择器的用法
选择元素
|
|
从上述的代码中可以看出,BeautifulSoup解析出的标签返回任然是一个BeautifulSoup的Tag类,可以再次进行筛选
获取名称
|
|
获取属性
|
|
获取内容
|
|
嵌套选择
|
|
子节点和子孙节点
contents
|
|
children
|
|
descendants
|
|
父节点和祖先节点
parent
|
|
parents
|
|
兄弟节点
|
|
标准选择器
find_all (返回所有元素)
可根据标签名、属性、内容查找文档
name根据标签名
|
|
attr根据属性
|
|
text根据文本
|
|
find(查找单个)
|
|
其他用法
|
|
CSS选择器
通过select()直接传入CSS选择器即可完成选择
普通选择
|
|
获取属性
|
|
获取内容
|
|
